Apache Kafka – A Scalable Messaging System
Kafka is a distributed messaging system that allows to publish-subscribe messages in a data pipeline. It is a fast and highly scalable messaging system and is most commonly used as a central messaging system and cnetralizes communication between different and large data systems.
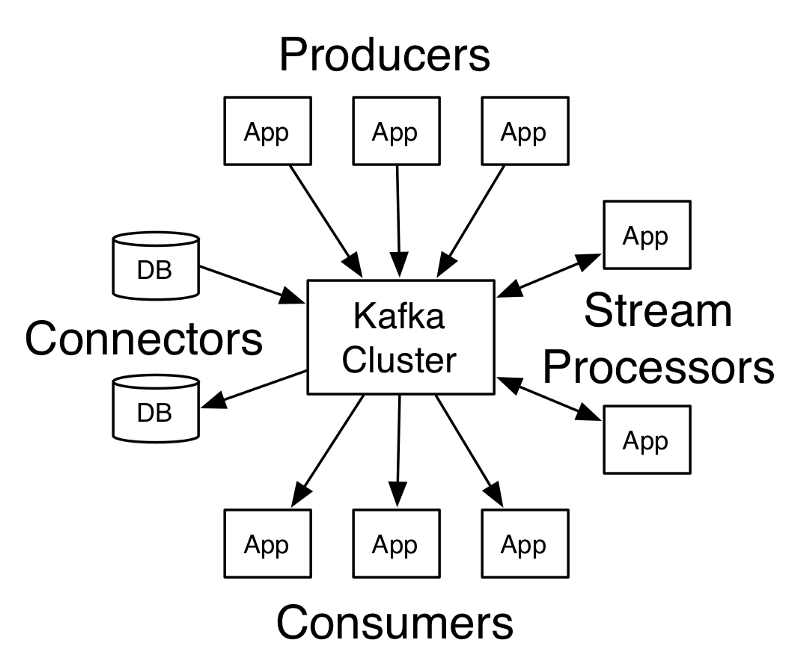
Image reference: http://kafka.apache.org/documentation.html
Advantages of using Apache Kafka
1.) Highly Scalable:
As mentioned earlier, one of the major advantages of using Kafka is that it is highly scalable. In times of any node failure, Kafka allows for quick and automatic recovery. In a world that now deals with high volumes of real-time data, this feature makes Kafka a hands down choice for data communication and integration.
2.) Reliable and Fault – Tolerant:
Kafka helps to replicate data and also supports multiple subscribers. Thus, in case of any failure there is no fear of data crash. Kafka is a fault-tolerant messaging system, thus making it a highly reliable pub-sub messaging system among the many others
3.) High Performance:
Kafka is super efficient at handling real-time and complex data feeds with high throughput and lesser delays. The data and stored messages can run into terabytes, yet Kafka delivers high performance and the best companion for any enterprise Hadoop infrastructure.
Popular use case scenarios for Apcahe Kafka
1.) Messaging
A message broker is used for many reasons such as separating data lines from data producers, buffer and load unprocessed images etc and Kafka works as the best messaging broker to support all these activities. Also, with the credibility of being fault-tolerant and highly scalable, Kafka is a good solution for processing large scale messages.
2.) Website Activity Tracking
The main use of Kafka was to help to track and analyze real-time feeds of complete website activity such as page views, search, publish and subscribe and any activity that user performs on the site. All these activities are stored as separate topics in the data pipeline.
Kafka is also used to track high volumes of data activities as each page view can generate multiple messages.
3.) Log Aggregation
Kafka helps to collect distributed data files and puts them all together in a central place for processing. It de-clutters the extra details and only gives log and event data that has been recorded. Kafka is better suited from other log-centric systems because of greater performance and durability due to data replication.
4.) Stream Processing
Kafka helps to process data in multiple stages where the raw input data procured from Kafka topics is aggregated, enriched and transformed into new topics for further data mining.
Right from crawling content, to publishing it and further categorizing it under relevant topic and then attempting to recommend the content to users, Kafka does it all! The processing pipeline is quick and has low latency. It also provides real-time data graphs and hence is considered to be the most reliable stream processing tool.
Thus, Kafka is an amazing big data processing tool that most MNCs such as LinkedIn, Twitter, Pinterest and many more use as their publish-subscribe messaging system and also to track data. Its durability and scalability give Kafka an edge over other big data solutions.


